
Improve trust in text classification models using HuggingFace and BaaL
As we introduce more deep learning models in production, it is essential that users trust decisions made by our models.
One of the worst experiences for a user is when a model makes a wrong prediction with high confidence, they would stop trusting the model as the confidence does not match the expected performance.
This is what we call calibration, we can compute how well a model is calibrated using the Expected calibration error or ECE. This metric can be summarized as the weighted average of the difference between a model’s confidence and its accuracy at multiple bins of confidence. Below, we have a visual explanation coming from the excellent paper of Guo et al. 2017.

We want to minimize the gaps in this diagram. In this post, we will improve a model’s calibration using HuggingFace and BaaL. The notebook is available here.
Load our HuggingFace Pipeline and Dataset.
The HuggingFace ecosystem is simple to use and in just a few lines of code, we can have a pre-trained model and its associated dataset. We will use the well-known SST2 dataset along with a DistilBERT model.
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, TextClassificationPipeline, AutoModelForSequenceClassification
pipeline : TextClassificationPipeline = load_model("distilbert-base-uncased-finetuned-sst-2-english", use_cuda=False)
dataset : Dataset = load_dataset("glue", "sst2")["validation"]
Use MC-Dropout for better predictions with BaaL.
BaaL is a Bayesian active learning library that will help us improve ECE.
To do so, we will use Bayesian deep learning to gather multiple predictions for the same input. The key idea is that by drawing multiple sets of weights from the posterior distribution, the average prediction will be better than a single. This is not unalike Ensembles, but without retraining, we will call this a Bayesian Ensemble. Generally, Ensembles are better but require more computational power.
While we have ways to separate the model’s uncertainty from the data’s uncertainty, we will focus on the predictive uncertainty which is ultimately what will affect the calibration of the model.
Next, we will compare the regular model’s ECE and its Bayesian alternative. BaaL will help us prepare the model and compute the ECE.
To prepare the model, we simply do:
from baal.bayesian.dropout import patch_module
pipeline.model = patch_module(pipeline.model)
This will modify the model of our loaded pipeline to use Dropout at test time. We now run the model 20 times and compute the average prediction before computing the ECE and the Accuracy. Below, we show the difference between both approaches.
| Bayesian | Frequentist | |
|---|---|---|
| ECE | 0.063 | 0.0802 |
| Accuracy | 0.903 | 0.910 |
Impact of the iterations parameters
Using 20 iterations, we improved our model’s calibration by a significant margin. This is quite good!
Let’s investigate how more iterations mean better ECE.
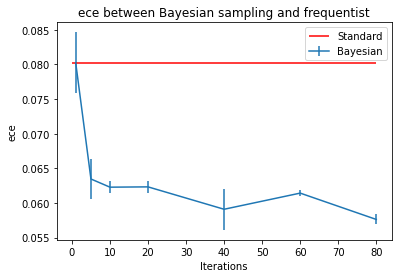
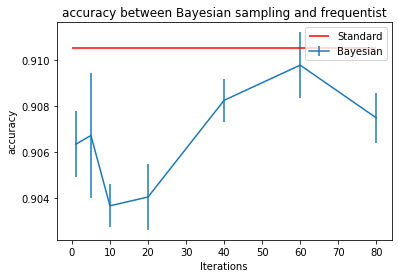
Discussion
Testing our ECE at multiple iterations, we see that it converges quickly after ~40 iterations. While the accuracy takes a hit in the beginning, it quickly comes back. Of course, sampling brings noise to the prediction, but it stabilizes quickly with enough iterations.
Conclusion
Using a couple of lines of code, we can improve our model’s calibration. While we now require multiple predictions per input, the cost should not be too prohibitive for most cases. If you have access to large GPUs, I suggest duplicating your dataset and aggregating the predictions at the end.
I did this analysis on an academic dataset where Bayesian deep learning has been extensively studied. In my next blog post, I will analyze a dataset closer to real data: CLINC.
Links
I have gone quickly over Bayesian deep learning and MC-Dropout so here are some resources if you want to know more:
Earlier, I mentioned model uncertainty versus data uncertainty, if you would like to know more I would recommend the following resources:
- Bayesian active learning for production, a systematic study, and a reusable library (Atighehchian et al. 2020)
- Synbols: Probing Learning Algorithms with Synthetic Datasets (Section 3.3) (Lacoste et al. 2020)
If you have any questions or suggestion, please contact me at:
- @Dref360 on Slack
- frederic.branchaud.charron@gmail.com
I’m thinking of more blog posts combining HuggingFace and BaaL, let me know if that interests you!